サイト内の現在位置
コラム
LLM(大規模言語モデル)とは?
生成AIとの違いや仕組みを解説

更新:2024.07.09(公開:2024.02.29)
ビジネスの世界で注目を集めている「LLM(大規模言語モデル)」とは、膨大なテキストデータと高度なディープラーニング技術を用いて構築された、自然言語処理(NLP:Natural Language Processing)と呼ばれる分野における革新的な技術を指します。2024年12月には、OpenAI社の最新LLMモデルである「o3-mini」が発表され、さらに話題を集めています。
本記事では、具体的なビジネス活用の最新事情のほか、「ChatGPT」や「生成AI」などの関連ワードも交えて分かりやすく解説します。
INDEX
- LLM(大規模言語モデル)とは
- 言語モデルとは
- ファインチューニングとは
- LLM(大規模言語モデル)と生成AIやChatGPTとの違い
- 生成AIとの違い
- ChatGPTの違い
- LLM(大規模言語モデル)の仕組み
- STEP① トークン化
- STEP② ベクトル化
- STEP③ ニューラルネットワークを通した学習
- STEP④ 文脈(コンテキスト)理解
- STEP⑤ デコード(出力ベクトルに修正しテキストへ変換)
- LLM(大規模言語モデル)の歴史
- LLM(大規模言語モデル)の活用事例
- NECの日本語LLM(大規模言語モデル)
- LLM(大規模言語モデル)の課題
- まとめ
LLM(大規模言語モデル)とは
LLM(Large Language Models、大規模言語モデル)とは、膨大なテキストデータと高度なディープラーニング技術を用いて構築された、自然言語処理(NLP:Natural Language Processing)と呼ばれる分野における革新的な技術です。従来の言語モデルと比較して、「計算量(コンピューターが処理する仕事量)」「データ量(入力された情報量)」「パラメータ数(ディープラーニング技術に特有の係数の集合体)」という3つの要素を大幅に強化することで、より高度な言語理解を実現しています。
LLMはファインチューニングすることによって、テキスト分類や感情分析、情報抽出、文章要約、テキスト生成、質問応答といった、さまざまな自然言語処理タスクに適応可能となります。
言語モデルとは
言語モデルは、人間が話したり書いたりする「言葉」や「文章」をもとに、単語の出現確率をモデル化する技術です。具体的には、大量のテキストデータから学習し、ある単語の後に続く単語が、どのくらいの確率で出現するのかを予測します。たとえば、「私の職業は」という文章の後に続く単語として、「医者です」「SEです」「保育士です」は確率として高いと判断し、「黄色」「海」などは低いと判断していき、言語をモデル化していきます。こうして言語モデルは、単語の出現確率を統計的に分析することで、人間の言語を理解し、予測することができるようになります。
ファインチューニングとは
ファインチューニングとは、機械学習における用語で、微調整という意味です。具体的には、あるデータセットで学習済みのモデルを別のデータセットを使って再トレーニングし、新しいサービスやタスク向けに機械学習モデルのパラメータを微調整します。
LLM(大規模言語モデル)と生成AIやChatGPTとの違い
ここではLLMと、昨今話題の「生成AI」と「ChatGPT」の違いについて簡単に解説します。
生成AIとの違い
LLMと生成AIは、どちらも人工知能(AI)の一種ですが、階層と特化分野において異なる特徴を持っています。生成AIとは、テキスト、画像、音声などのデータを自律的に生成できるAI技術の“総称”です。一方、LLMは、自然言語処理に特化した“生成AIの一種”であり、膨大なテキストデータから学習することで、より高度な言語理解を実現したものです。


ChatGPTとの違い
LLMは大規模言語モデルのことを指しますが、ChatGPTはそのLLMを応用して、特に対話に特化した機能を持つAIモデル、あるいはこれを開発したOpenAI社の提供するサービスを示します。 LLMはあらゆる言語タスクに対応できる一方、ChatGPTはユーザーとの自然な会話を重視し、入力に対して適切な応答を生成することに最適化されています。新たなモデル「o3-mini」では、推論能力が大幅に向上し、高速な応答が可能となりました。

LLM(大規模言語モデル)の仕組み
LLMがどのように言語を理解し、言葉を生み出すのか。大きく以下の5つのステップで解説できます。
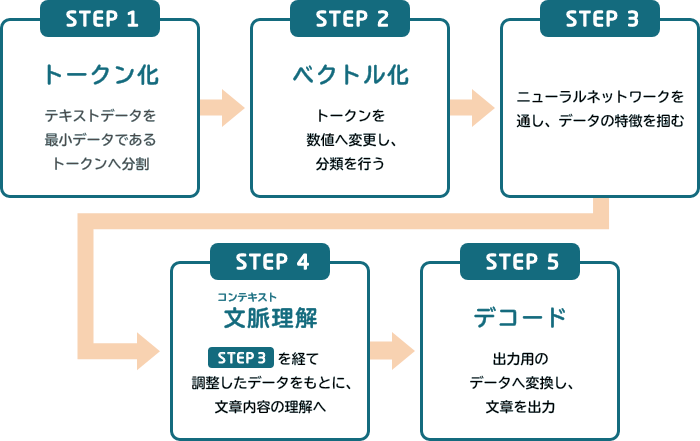
STEP① トークン化
トークン化とは、テキストデータをコンピュータが理解しやすいように、小さな言葉の塊であるトークンに分割する処理を指します。トークンとは、単語や句読点、記号など、テキストデータにおける最小単位の要素です。英語の場合、単語や句読点がトークンとなります。テキストデータはそのままではコンピュータが理解できないため、数値データに変換する必要があります。トークン化は、数値データに変換するための前段階として行われます。
トークン化は、LLMがテキストデータを理解し、処理するために必要な重要な技術です。トークン化によって、コンピュータがテキストデータを効率的に処理できるようになり、機械学習モデルの精度も向上します。
STEP② ベクトル化
ベクトル化とは、トークン化されたデータを数値のベクトルに変換する処理を指します。STEP①でも解説したように、トークン化によって分割されたデータは、そのままではコンピュータが解析できません。ベクトル化は、トークンを数値に変換することで、コンピュータが情報を解析できるようにするための処理です。ベクトル化によって、コンピュータがトークン(言葉の最小単位)を数値として扱うことができるようになり、より高度な言語理解を実現しています。
STEP③ ニューラルネットワークを通した学習
ニューラルネットワークは、LLMの核心的な部分であり、多数の層からなる複雑な構造を持っています。テキストデータがニューラルネットワークを通過する際に、各層でデータは変換され、調整されます。この過程でモデルは入力データの特徴を抽出し、学習を行います。また、ニューラルネットワークは、単語の出現確率だけでなく、単語間の関係性や文脈も考慮して学習するため、テキストデータの文脈やニュアンスを理解できるようになります。つまり、ニューラルネットワークによる学習によって、LLMは高度な言語処理能力を獲得できるのです。
STEP④ 文脈(コンテキスト)理解
文脈(コンテキスト)理解は、LLMがテキストデータを理解するために必要不可欠な機能です。ニューラルネットワークを通して入力されたテキストの文脈や背景を把握し、それに基づいて意味の解釈を行うため、LLMは単なる単語の並びではなく、文全体の意味や、文と文との関連性を理解できるようになります。
たとえば「私は川を渡るために橋を渡った」という文章の場合、LLMは文脈理解によって、「橋」が「箸」ではなく「川を渡るための構造物」であると判断できます。文脈理解は、LLMが人間に近い理解力と応答能力を発揮するために必要不可欠な機能。LLMは、文脈理解によって様々なタスクを実行できるようになるのです。
STEP⑤ デコード(出力ベクトルに修正しテキストへ変換)
テキスト変換は、LLM処理の最終段階であり、出力ベクトルを修正し、人間が理解できる自然なテキストデータに変換する作業です。LLM内部で処理していたベクトルデータを修正し、最も確率が高い単語やフレーズを選択することで、人間が理解できる自然なテキストデータの形に出力します。これによって、LLMは人間と自然なコミュニケーションをとれるようになるのです。なお、テキスト変換は「デコード」とも呼ばれます。
LLM(大規模言語モデル)の歴史
下表は、2018年以降のよりモダンなLLMについて、その概要の一部をまとめたものです。
| 発表年 | 企業名 | LLM(大規模言語モデル) |
|---|---|---|
| 2018 | BERT | |
| 2020 | OpenAI | GPT-3 |
| 2021 | LaMDA | |
| 2022 | PaLM | |
| 2022 | Meta | LLaMA |
| 2023 | OpenAI | GPT-4 |
| 2024 | OpenAI | GPT-4o |
| 2024 | OpenAI | o1 |
| 2024 | OpenAI | o3-mini |
・言語モデルは基本的にTransformerの仕組みを利用。
・Transformerとは、2017年に発表された「Attention Is All You Need」という論文で示されたディープラーニングのモデル。
従来の技術の仕組みを簡易化することにより、より早く制度の高い結果を出せるようになった新技術。
2024年12月には、新しいLLM「o3-mini」が公開されました。
なお、ほとんどの言語モデルは、基本的にTransformer(トランスフォーマー)と呼ばれるディープラーニングモデルの仕組みを利用しています(ChatGPTの「T」もTransformer)。Transformerは、2017年に発表された画期的な研究論文『Attention Is All You Need』で示された技術です。従来の技術と比べて処理を簡易化し、より迅速かつ高精度な結果を出せるようにしたことが特長で、昨今の急激なLLMの進化はこのTransformerが支えていると言っても過言ではないでしょう。
LLM(大規模言語モデル)の活用事例
LLMは、自然言語処理に特化したAIモデルです。そのため、言語を用いるあらゆる分野への活用が期待されています。たとえば、対話/文章要約/翻訳/入力の続きを予測/文章の分類や言い換え/キーワードの抽出/入力されたプログラムのコードなどのバグチェック/情報の抽出などにおいて有用とされており、ビジネス分野では以下のような用途に役立つとされています。
- デジタル上でのユーザーとのコミュニケーション全般
- IT分野での情報検索や意味解釈の補佐。文章の要約
- マーケティング分野での広告のテキスト作成
- 議事録内容の抽出
もちろん、ビジネス活用以外にも社内向けの情報管理や教育など、さまざまな方面での活用が期待されています。
NECの日本語LLM(大規模言語モデル)
近年注目を集めている生成AIは、日本語処理において課題があるとも言われています。ビジネス利用する場合は、日本語に関する知識量及び文書読解力の点で高い性能が求められます。
NECが開発したLLMは、知識量に相当する質問応答や推論能力に相当する文書読解において世界トップレベルの性能を達成※1。高い性能を実現しつつパラメータ数を抑えることで、消費電力を抑制するだけでなく、軽量・高速のためクラウドおよびオンプレミス環境でも運用が可能になっています。
さらにNECは、高速性と高性能の両立を目指し、新たに「cotomi Pro」「cotomi Light」※2を開発。総合的なタスクに対する高い処理能力と応答までの時間短縮が両立可能となりました。NECの日本語LLMは日本語に特化しており、軽量で高性能なため、特に個人情報を扱う秘匿性の高い業務などでの活用が期待されています。
※1 2023年12月時点
NEC開発のLLM「cotomi」の比較評価表などはこちら
※2 「cotomi Pro」「cotomi Light」について
LLM(大規模言語モデル)の課題
LLMは様々な可能性を秘めていますが、いくつか課題も存在します。ひとつが「ハルシネーション」です。ハルシネーションとは、LLMが事実とは異なる情報や、文脈とまったく関係ない内容を出力してしまう現象です。日本語では「幻覚」と訳されます。ハルネーションには「Intrinsic Hallucinations」という学習に用いたデータと異なる事実を出力するケースと「Extrinsic Hallucinations」という、学習に用いたデータには存在しないことを出力するケースがあります。
ハルシネーションは、データ内に偏りや誤った情報が含まれている学習データの問題、モデルが誤った情報を生成しやすい構造・学習方法になっているAIモデルの学習プロセスなどの問題によって引き起こされます。ハルシネーションは、システムの進化と共に減っていくと考えられますが、言語モデルの性質上、完全な防止は難しいでしょう。そのため、ユーザーもハルシネーションが起こることを念頭においた上での利用が必要になります。
また、もうひとつ「プロンプトインジェクション」という問題も顕在化しています。プロンプトインジェクションとは、悪意のあるユーザーが巧妙なプロンプトを入力することで、LLMに本来禁止されている機能を実行させたり、不適切な回答をさせたりする攻撃手法。プロンプトインジェクションによって、企業の秘密情報や第三者の個人情報が開示されたり、根拠のないデマが拡散されたりするというリスクが発生します。
プロンプトインジェクションを防ぐには、入力できるプロンプトを制限するほか、出力結果をフィルタリングし、ユーザーに対してプロンプトインジェクションの危険性を啓蒙するやり方が考えられます。
LLMは、さまざまな可能性を秘めた技術ですが、ハルシネーションやプロンプトインジェクションなどの課題も存在します。これらの課題を克服するために、技術開発とユーザー教育の両面から取り組むことが重要です。
まとめ
かつては夢の技術と思われていたLLMですが、今や誰もが当たり前に利用できる一般的なビジネスツールとなっています。現実にすでに多くの企業がLLMを自社ビジネスに導入しており、すでに大きな成果を上げている事例も存在します。
見過ごせないリスクもまだまだ存在するLLMですが、これを無視して自社ビジネスをドライブさせるのは難しい時代になりつつあるといえるでしょう。まだLLMを利用していないが興味はあるという企業は専門家に相談し、どういった用途にLLMを利用できるか、そのために必要なことは何か、リスクを抑えるためにどうすればよいのかを見極めるところから初めてはいかがでしょうか?











