サイト内の現在位置
専門家コラム
ノーコード・ローコード開発の前に
情シスは「データモデル」を確立せよ
- 【執筆者】渡辺幸三氏
- 業務システム開発者

UPDATE : 2021.08.20
業務システムの開発や保守を合理化する「ノーコード・ローコード開発」が注目されている。ユーザ企業がシステムに対する主体性を取り戻すための有望な技術だが、企業システム統制の観点から見ると、落とし穴が隠れていると言う。
システム設計に関する多くの著書で知られ、自らもローコード開発ツールを開発・公開している渡辺幸三氏が、システム内製化の最重要課題である「事業向けデータモデルの確立」について詳しく解説する。
INDEX
- 「コードの大山塊」に疲弊する情シス部門
- アジャイル開発の落とし穴:プロセス指向
- 事業のデータモデルを確立せよ
- オーディションで業者のスキルを値踏みする
- システム開発・刷新を成功させるための3原則
- 【原則1】コードを削減せよ
- 【原則2】データモデルを確立せよ
- 【原則3】長期の開発計画を立案せよ
「コードの大山塊」に疲弊する情シス部門
コンピュータが商用利用されるようになって以来、業務システム(基幹システム)の企画や要件定義はユーザ企業の情シス部門が担っていた。ところが、2000年代になるとそれらの重大な役割を持つ情シス部門の存在感が急速に希薄になった。原因はいくつかある。
まず、2000年頃に流行ったERPパッケージの導入によるものだ。グローバルスタンダードや業界のベストプラクティスといった煽り文句に惹かれ、多くの企業がこぞって導入した。しかし、ただでさえ見通しの悪い巨大ソフトウエアに大量のアドオン(カスタマイズ機能)が組み込まれた結果、内部構造がブラックボックス化し、保守ベンダーの意向に逆らえなくなった。システムは使いにくく、運用・保守コストは高止まったままだ。
パッケージを使わずJavaなどのプログラミング言語を用いたスクラッチ開発(ゼロからの手作り)に挑んだ企業でも、同様の問題が起こった。2000年頃から業務システムはWebアプリとして作り替えられるケースが増えたが、その特性上、以前のタイプとは桁違いに複雑なソフトウエアと化す。この場合もERPと同様に、事業の命運を保守業者に握られた。ちょっとした修正をするにしても、妥当性の分からない高額な見積額を受け入れざるを得なかった。
全面刷新を避け、COBOLなどで組まれたレガシーシステムを使い続けている企業もあるが、彼らとて安泰ではない。古いシステムを使い続けているのは、あまりに膨大なコードゆえに刷新しようがないためで、古臭く使いづらいUI(ユーザインタフェース)に対する社内の評判は芳しくない。ITの専門家集団であるはずの情シス部門のプレゼンスは低下するばかりだ。
これらのパターンに共通するのは、様々なタイプの「プログラムコードの峨峨たる大山塊」の存在である。コードはシステムの動きを制御するために欠かせないものだが、多過ぎると情シス部門を疲弊させる厄災となる。
そんな状況で2010年代に入ると、労働集約的なコーディング作業を合理化するための実装基盤が国内外で登場した。それらはコードを書かずに済むこと(ノーコード開発)や、最小限のコーディングで済むこと(ローコード開発)を謳っている。これらを用いてシステムを内製化することで、外部業者に奪われた主導権を取り返し、社内での存在感を強化できる―。情シス部門がそのように期待するのは当然だった。
アジャイル開発の落とし穴:プロセス指向
しかし現実は甘くなかった。「ノーコード開発ツール」は開発のプロでなくてもそれなりのアプリを開発できることが売りで、一定以上のITリテラシーを有するエンドユーザに受け入れられた。しかしその結果起こったことは、統制されていない野良アプリ(シャドウITともいわれる)の乱立だった。何のことはない。従来型野良アプリの代表であった「Excelシートの山」に「ノーコード基盤で組み立てられたアプリの山」が追加されただけの話である。
最小限のコーディングで開発できることを謳う「ローコード開発ツール」も、ベンダーが勧める「アジャイル手法」という流行りの開発手法と結びつくことで、無用な混乱をもたらしつつある。
アジャイル手法では、「動くプログラム」の作成が優先される。2週間単位で小さめなアプリ群を組み立て、エンドユーザといっしょに動作確認しながら仕様品質を高めていく。じっさいローコード開発ツールを使えば、情シス部門のメンバーであれば「動くプログラム」は楽に組み立てられるので、ローコード開発ツールとアジャイル手法は相性の良い組み合わせに見えた。
しかし、このやり方には落とし穴があった。前述したようにアジャイル開発では「動くプログラム」を組み立てることが優先される。これを業務システム開発に適用すると、図1のようなソフトウエアが出来上がる。データはアプリが適切に動作するために存在する。つまりデータ処理プログラムが「主」で、データは「従」だ。このような考え方をPOA(プロセス指向アプローチ)という。
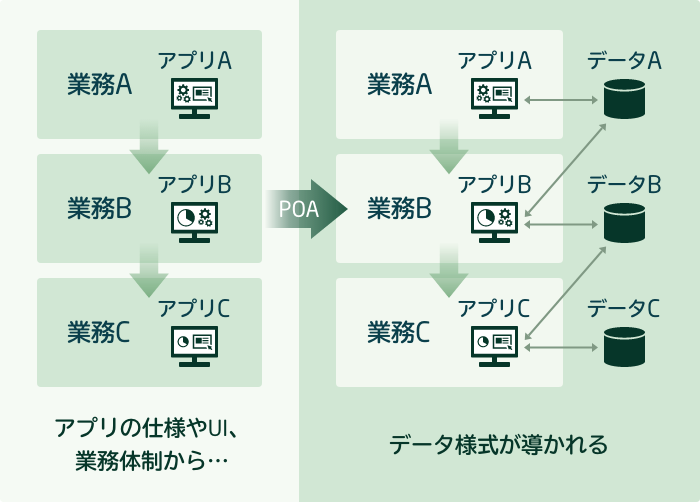
POAの何が問題なのか。まず、業務システムでは事業活動に関わる膨大なデータ項目(商品ID、顧客ID、受注数量といった項目のこと)が扱われる。それらはデータベースの構成要素であるテーブル上に配置されるが、アジャイル手法を含むPOAでは、それらが「データ処理単位(プロセス単位)」を基準として切り出されてゆく。その結果、多くのテーブルがデータ項目を重複的に抱えた形で出来上がる。遅かれ早かれ、どの値が正しく、どの値が間違っているのかわからない「データの不整合(矛盾)」が生じる。しかも、不整合をコードで補完するためにコード量が無駄に増えていかざるを得ない。生み出すデータを活用できない、運用・保守に多大の手間がかかる。そのような業務システムとなる。
こういった傾向は、ソフトウエア業界で流行している「マイクロ―サービス・アーキテクチャ(MSA)」の適用によってさらに拍車がかかっている。MSAでは、システム機能が小さめのサービス群に分割され、API(アプリケーション・プログラミング・インターフェイス)を介して連係する。それぞれのサービスは独自のデータベースを扱うことが許されるため、データベースの乱立とデータ項目の重複による不整合が避けられない。不整合はAPIを駆使することである程度は対処可能だが、異なるデータベース間での整合性維持の困難は「二相コミットの問題」として知られている。
MSAはもともと「稼ぐWebサービス」を開発・維持するために生まれた考え方で、疎結合(そけつごう・loose coupling)に分割されたサービスごとに専門チームが開発・保守を担う。各サービスは売上をもたらすので、それだけの人員が貼りつくことが許される。ところが、一般の業務システムは売上活動を支援するものであっても、有償サービスのように自身が売上を得るソフトウエアではない。そういったものを細かく分割してそれぞれにチームを張り付ける余裕などない。ようするに業務システムにMSAは向いていない。
事業のデータモデルを確立せよ
業務システム開発にアジャイルやMSA適用が失敗に終わることは、ある意味で必然であった。その原因はひとえに、システム化対象を含めた広域のデータモデルが認識されないまま、部分最適化を狙って開発が進められた点にある。「コード削減」は達成すべき課題ではあったが、それだけではまったく不十分だった。事業のデータモデルを確立し、すべてのシステム企画がそれを基礎として方向づけられる必要があった。
1990年代にCASE(Computer Aided Systems Engineering)ツールと呼ばれる技術が注目されたことがある。今でいうローコード開発ツールだったのだが、急速に廃れてしまった。その原因もやはり、業者側のデータモデリングに関する支援体制の不備、および「開発工数(コード量)が多いほど儲かる」という彼らのビジネスモデルにあった。筆者は当時、CASEツールを活用していた技術者であったため、そのことで何度も悔しい思いをした。そして現在、ローコード開発ツールのブームにも同様の危うさを感じている。
では、それほど重要なデータモデルとはそもそも何なのか。業務システムというものは「事業運営に関わるデータ項目を効果的に扱うためのしくみ」である。その事業運営に関わるデータ項目間に成立する数学的関係を表す図面―、それがデータモデルである。
身近な話題に沿った具体例を示そう。図2は「自治体向けワクチン接種管理」向けに筆者自身がまとめたデータモデルの一部だ。自治体による予防接種プログラム、接種日程、接種拠点、ワクチン、ワクチン在庫などのテーブルが載っている。配送や要員派遣に関するテーブルはこの図では省略されている(筆者のサイトhttp://dbc.in.coocan.jp/から全体をダウンロードできる)。
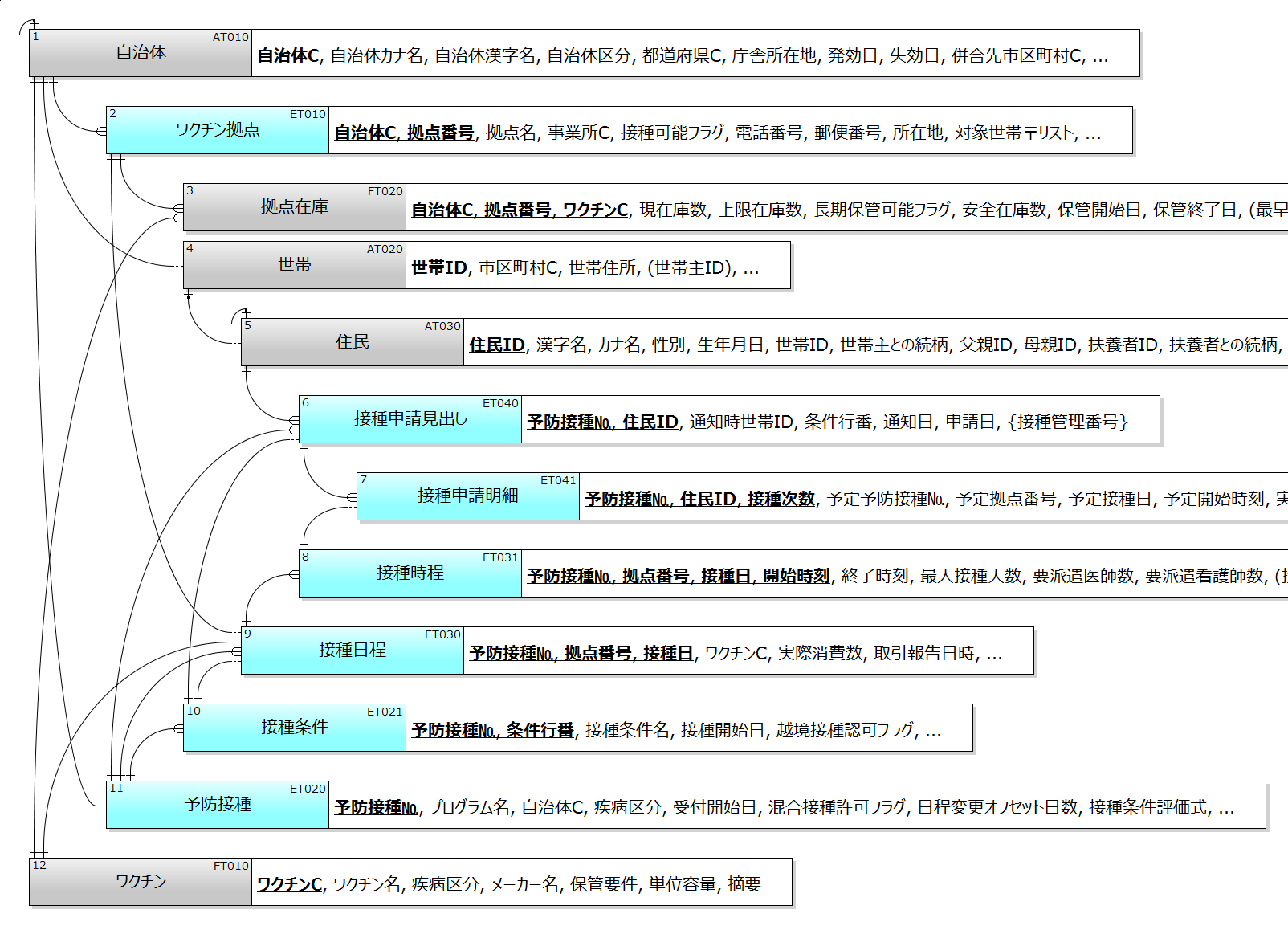
2021年春に始まった新型コロナワクチン接種だが、7月になって都道府県へのワクチン供給を削減する方針が発表された。その根拠として、都道府県によって在庫の余剰があるゆえと説明された。ところがその後、政府が都道府県別のワクチン在庫を正確に捉えていないことが明らかになり、2週間後に削減方針を撤回した。この問題は、政府主導で開発されたワクチン配送管理システム(V-SYS)と接種実績管理システム(VRS)とが別物であるゆえに生じている。その後、それらを連係させて自治体別の在庫数を示し始めたが、その数字に予約済未接種分の引当てが考慮されていない(考慮できない)ことがわかって、関係者を落胆させている。
これらは一般の在庫管理システムではあり得ない初歩的な設計ミスなのだが、図2のように包括的なデータモデルが事前に確立されていれば生じるはずもなかった。ワクチンの配送・在庫と、接種の予約・実施とは一蓮托生のもの、という認識がデータモデルを介して徹底されるからだ。データモデルなしでシステム開発することの無謀さ、また細かく分けたサービスを連係させて問題を解決しようとする手法の限界を示す残念な事例になった。
データモデルが「事業運営に関わるデータ項目間に成立する数学的関係を模式化した図面」であると説明したが、そこでいう「数学的関係」とは何のことか。図2に含まれる例をいくつか取り上げよう。
- ① y=f(x)
- ② y=世帯IDがxである世帯の自治体コード
- ③ z=f(x、y)
- ④ z=予防接種№がx、住民IDがyである接種申請の申請時世帯ID
- ⑤ d=f(a、b、c)
- ⑥ d=自治体コードがa、拠点番号がb、ワクチンコードがcである拠点在庫の現在庫数
中学の数学で学んだ①、③、⑤のような関数を、②、④、⑥のような社会的事物の関係に敷衍(ふえん)したものが、データモデリングにおける「関数従属性」である。z=f(x、y)において、xとyの組み合わせを識別子、zを従属子と呼ぶ。データ項目間の関数従属性をすべて明らかにし、識別子の値と従属子の値のペアがデータストア上の唯1カ所に記録されるように情報を構成することで、矛盾の生じないデータ構造が手に入る。
現代のデータベースの主流であるリレーショナルデータベース(RDB)は、数学の集合論を基礎として1970年代に誕生した情報技術だ。RDBを核に据える業務システムにおいて、データこそが「維持管理される主なる対象」であり、プログラムや業務体制は「データの整合性を維持するために用意される付属物」である(図3)。このような考え方をDOA(データ指向アプローチ)という。
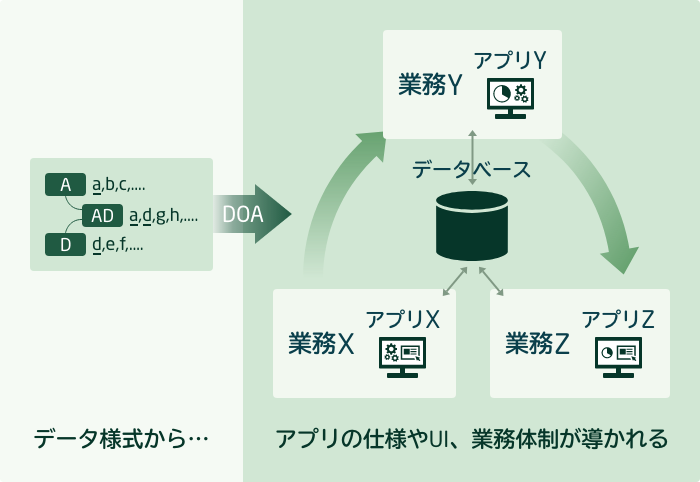
図1と比べてみてほしいのだが、POAにおいてシステムが扱うデータの様式は、UIやアプリや業務体制から導かれるとみなされる。DOAではその真逆だ。今でも多くのIT技術者はPOAでしか設計できないと思い込んでいるが、事業活動を支える業務システムは「情報管理システム」であり、その仕様は「管理すべき情報がどんな形をしているか」が明確でなければまとめようがない。言い換えると、「アプリや業務を実行するためにデータがある(POA)」か、「データを維持するためにアプリや業務がある(DOA)」かというシステム認識の問題である。この違いはシステム仕様のあり方に決定的な違いをもたらす。
したがって、情シス部門が一義的に管理・維持しなければいけないのは「コードの大山塊」ではなく「事業のデータモデル」である。そこからアプリの仕様や業務体制や開発計画を派生させてゆく―、そういった発想のコペルニクス的転回が求められている。Javaやローコード開発ツールといった実装基盤で組み立てられたコード群は、適宜破棄されてゆく。しかし、データモデルとそれに沿った実データは、事業が継続する限り保全されていかねばならない。つまり情シスは、生生流転するコードの大山塊ではなく、自社のデータモデルの維持・発展に関する専門家でなければならないということだ。
オーディションで業者のスキルを値踏みする
ここまでの説明で、データモデルやDOAの重要性についてご理解いただけたかと思うが、データモデリングを担えるIT技術者が極端に少ないという現実がある。イギリスではデータモデリングの専門家(データモデラー)がその希少性ゆえに全職業中もっとも年収が高いという調査もあるほどだ。まさに彼らの希少性ゆえに、日本でもPOA的な発想で作られた業務システムばかりになってしまっている。2000年頃にERPが受け入れられたのも、難読かつ適合性も劣っていたが、誰もまとめてくれなかった「事業データモデル」を提供してくれたおかげといえるだろう。
したがって、DOAを敢行するためには希少なデータモデラーと協業する必要がある。では彼らにどのようにリーチすればよいのだろう。ツールベンダーであろうとシステム・インテグレータであろうと、設計開発の実務を担うプロパー要員を多く擁している会社であれば、データモデラーはそれなりに所属していると考えていい。とはいえ、それらの組織でも腕のいい技術者は払底しているため、実際に彼らを起用できるかどうかはわからない。
そこで、複数業者を対象にした「オーディション」をお勧めしたい。実技評価を通して見定めた要員の起用を条件に、データモデリング、およびデータモデルにもとづくシステムの実装(プロトタイピング)を2時間程度の制限時間内で実施してもらうのである(図4)。その場で業者に渡すシステム要件定義は、A4用紙1~2枚でまとめた簡単な箇条書きでいい。
業者にとってオーディションは過酷ではあっても、その選別効果は強力だ。開発すべきシステムに関して意図的に省略された情報のみを与えることで、担当者の実務経験や業務知識の蓄積量がわかる。じっさいのところ、わずかなヒントにもとづいて描き広げられないとしたら、腕のいいデータモデラーとはいえない。
なお、データモデルのような専門的図面をユーザ企業は評価しようがないと思われるかもしれないが、心配御無用だ。そもそもデータモデルは、ある種の芸術作品や工学図面のように、生み出すのは簡単ではないが「鑑賞」は比較的容易な創作物である。少なくとも、ユーザ企業にとっての自分たちの事業を表すデータモデルを見て理解不能とは考えにくい。本当に理解不能であれば、データモデルの品質が悪いゆえに他ならない。
プロトタイプ(データモデルに沿って動作するシステム)をその場で組み立ててもらうことで、業者の実装スキルも判定できる。もっともらしいデータモデルを提出するだけで実装をやれない業者を信用してはいけない。なぜならデータモデルの妥当性は、それを実装して動作確認するまでわからないからだ。実装によって検証されていないデータモデルは「絵に描いた餅」、あるいは施工途中で倒壊する高層ビルの設計図のようなものだ。
さらにオーディションを通じて、業者が合理化に積極的であるかどうかもわかる。じっさい、ローコード開発ツールが普及した結果、短時間でプロトタイプを組み立てることが可能になった。Javaあたりでスクラッチ開発するスタイルでは到底望めない生産性をはじき出せる。厳しい時間制限を課すことで、工数主義的で旧弊な業者を簡単にスクリーニングできるのである。
さて、システムの新規開発や刷新にあたってデータモデルを確立することの重大さに比べたら、開発ツールの選定は二義的な問題ではある。データモデルがなければ、開発単位を適切に切り出せないし、長期計画もたてられないからだ。とはいえシステム開発を成功させるために、開発ツールの選定は「最後の1マイル問題」として無視できない。立派なデータモデルを手に入れたとしても、それを実現できないツールであればまた選定し直す羽目になる。
じつは開発ツールの選定においても、事前に確立されたデータモデルは決定的な効果をもたらす。ようするに、「データモデルをそのままの形で実装できるツール」を探せばよい。というのも、ツールによってはデータモデルをそのままで実装できないものがあるからだ。たとえば、全テーブルの主キーを同じ形式(たとえばidの単独主キー)にすることを強制するツールが存在する。テーブルの主キーはテーブル定義の生命線なので、その改変を強制するツールはお勧めできない。オーソドックスなデータモデルを基礎としない開発ツールは避けよう。
システム開発・刷新を成功させるための3原則
これまでの説明をまとめて、現代の情シスがシステム開発・刷新を成功させるための3つの原則を示そう。参考にしてほしい。
【原則1】コードを削減せよ
ユーザ企業の情シス部門は「コードの峨峨たる大山塊」に押しつぶされそうになっている。業務システムに含まれるコードの徹底的削減こそ喫緊の課題だ。COBOLだろうがJavaだろうが、ちまちまとコーディングしながら業務システムを開発・維持していては、情シス部門の弱体化ばかりか、本業にも差し障りが出かねない。ローコード開発ツールを含めて、合理化手段を真剣に検討しよう。
【原則2】データモデルを確立せよ
合理化手段の選定以上に「データモデルの確立」に心をくだこう。データモデルは「正しく構造計算された高層ビルの設計図面」のようなものだ。それなしで進めれば、ローコード・ノーコード開発であろうがスクラッチ開発であろうが、業務システムは開発途上で倒壊(デスマーチ化)するか、まともに使えないシロモノとして完成する。そのためには、協働できる腕の良い設計技術者を、金のわらじを履いてでも探し出そう。
【原則3】長期の開発計画を立案せよ
事業を支える情報の形がデータモデルとして「見える化」されたなら、事業システムの長期的な開発・刷新計画を立てよう。なにしろデータモデルが明らかなので、現行システムの弱点や刷新緊急度も見えてくる。無駄なく無理のない開発計画が得られるし、今流行りのDXを進めるための基礎にもなる。そのときこそ、情シスは経営者の右腕として本来の力を発揮できるようになるだろう。

■執筆者プロフィール
渡辺幸三(わたなべこうぞう)
業務システム開発者。データモデリングツールX-TEA Modeler、ローコード開発ツールX-TEA Driverの作者。システム設計に関する多くの著作がある。近著は「システム開発・刷新のためのデータモデル大全」(日本実業出版社)。
著者のサイト「データモデリング手法とレファレンスモデル http://dbc.in.coocan.jp/ 」
ブログ「設計者の発言 https://dbconcept.hatenablog.com/ 」












